



The Inference Interference
How to design verifiable inference that’s not slow


Blind trust in black-box AI apps is a ticking time bomb. It threatens to destroy our faith in the technology. Take ChatGPT. Users are forced to rely on unverifiable claims about what models are generating their inferences. Recent performance degradation of GPT-4 has heightened suspicions. People wonder if OpenAI even using the advertised model version. This erodes user confidence. This highlights the urgent need for verifiability.

Decentralized AI networks amplify this problem, as nodes host various models and compete for users' attention and money. We need a way to verify their claims and protect clients from fraud. For example, paying top dollar for the latest LLAMA outputs but getting inferior model results. The stakes couldn't be higher in a decentralized AI ecosystem.
The solution to this is Verifiable inference, using mechanisms to verify the use of specific models for generating inferences. This enables honest competition and protects clients.
While zero-knowledge proofs as a solution have been explored extensively by the decentralized AI community, and we discussed it in-depth in a previous article, they are currently too slow and expensive. At Bagel, we have investigated more practical and widely used alternatives from the traditional AI world, such as watermarking (Jia et al. 2021) and fingerprinting (Chen et al. 2019). Initially developed to prevent model extraction attacks, these methods also serve as unique model identifiers thus enabling verifiability. Compared to zero-knowledge approaches, they offer enhanced efficiency and ease of use, better aligning with current applications of verifiable deep learning models.
Today, we're open sourcing our research. Our goal is to empower the decentralized AI community and inspire builders to explore diverse, high-performance solutions from traditional AI. Together, we can create a more robust decentralized AI ecosystem that benefits the mainstream AI market.
If you're in a rush, we have a TLDR at the end.
Watermarking
How it works
In the landscape of machine learning, protecting foundation model as an intellectual property (IP) rights is a paramount concern. Enter watermarks – a clever defensive mechanism against model extraction attacks. Just like classical digital watermarking, a form of steganography where a message is concealed within a digital object, watermarks for machine learning models serve as a guardian of ownership, authenticity, and integrity. They help safeguard IP and enforce licenses, ensuring that the hard work of model creators doesn't go unrecognized.
Lederer et al. (2023) outline a plethora of characteristics that a watermark for a machine learning model must possess, but three stand out as the most crucial:
Effectiveness - Effectiveness means that the watermark can be verified at any time by the model's creator.
Fidelity - Fidelity ensures that the model's accuracy remains unaffected by the watermark's presence.
Robustness - That's the watermark's ability to withstand a barrage of attacks, from fine-tuning and model compression to watermark detection, removal, overwriting, or invalidation.
But how does the magic happen? Any watermarking embedding method consists of two algorithms: an extraction algorithm that retrieves the watermark from a model, and a verification algorithm that confirms its presence.
There are two main families of watermark embedding techniques: i) white-box watermarking and, ii) black-box watermarking. The general process of watermarking is illustrated in the figure below.
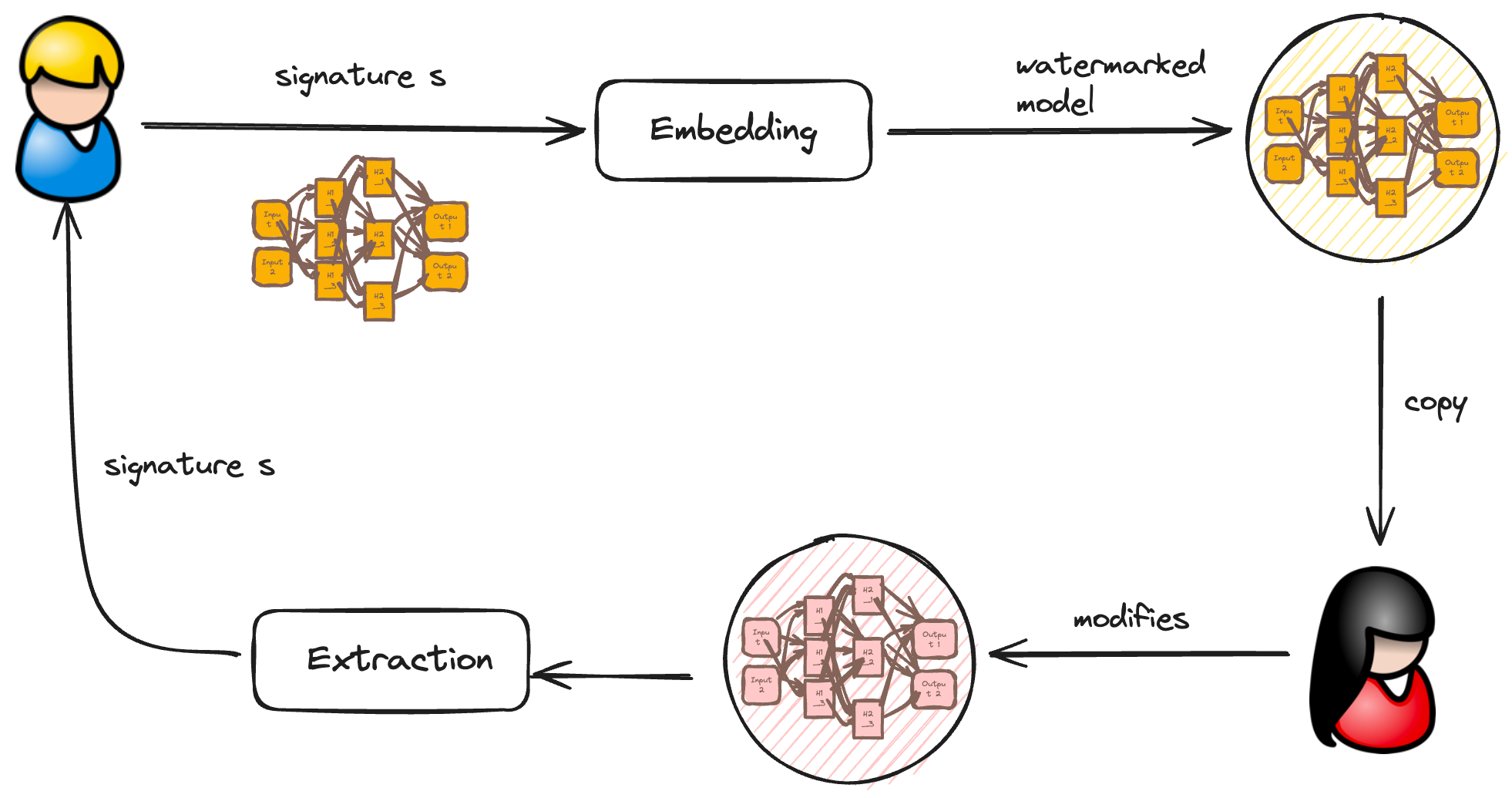
White-box watermarking requires full access to the model. The idea is to embed a signature s into the model's weights during training by adding an extra term to the loss function. This is done carefully to maintain the model's accuracy. The embedding is achieved by modifying the loss function through a regularizer parameter. Let w be a vector of all weights in a model. The goal is to embed s into w using an embedding matrix M, which acts as a secret key usually held by the model owner. The watermark is extracted by applying M to the weight vector w, followed by a threshold function (see Nagai et al. (2018) for details).
Black-box watermarking, on the other hand, only requires query access to the model. It creates backdoors on data using data poisoning. In this context, a backdoor is a set of input-output pairs known to the model owner that triggers a behavior not predictable by model consumers. For example, deliberately adding wrong labels to data points. The goal is to ensure that the model performs correctly on the main classification task, but the backdoor exhibits a specific behavior defined by the model owner.
Next we show two applications of watermarks in the context of verifying ownership of models and verifying inference from models.
Watermarking for Verifiable Inference
Public Models
Black-box watermarking is a game-changer when it comes to verifiable inference for public models. It's like a secret handshake between the model creator and the user, ensuring that the model is authentic and trustworthy.
Here's how it works: the model creator embeds a watermark and then discloses its presence to the world. It's like a badge of honor, a mark of quality. Any user who interacts with the model can then authenticate it, verifying that it's the real deal.
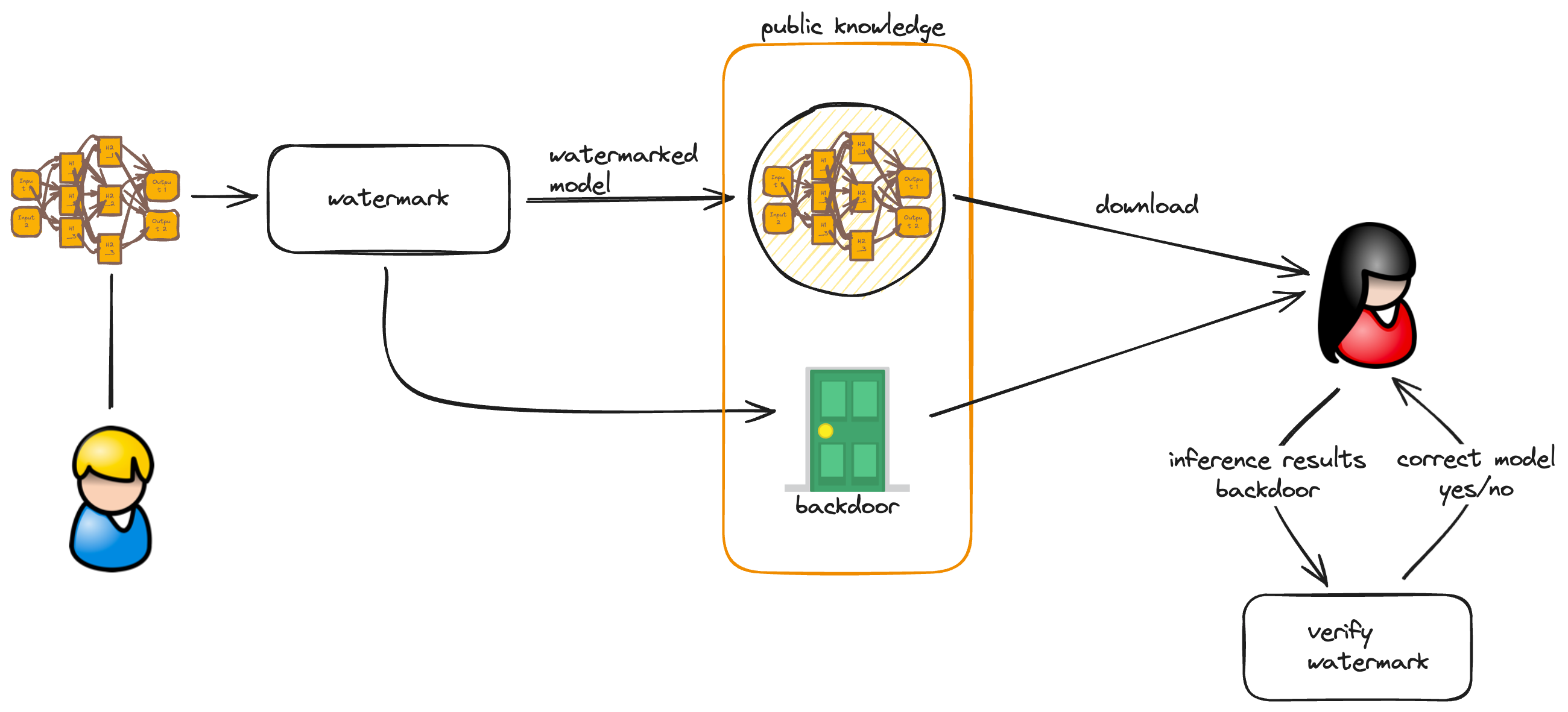
Zhong et al. (2020) took this concept to the next level. They developed a black-box watermarking technique that adds new labels to inputs that have nothing to do with the original dataset. It's like adding a secret code that only the model creator knows.
When a user wants to verify the watermark, they simply query these special inputs. If the watermark is present in the inference results, it's a clear sign that the model is authentic. It's like a digital signature that can't be forged.
Chen et al. (2019) took a slightly different approach. They generated watermark keys and used fine-tuning to embed a signature in the model. It's like hiding a secret message in plain sight.
With the watermark keys in hand, any user can interact with the model and extract the signature through its predictions. It's like unlocking a hidden layer of authentication, ensuring that the model is genuine and trustworthy.
Private Models
When a machine learning model is privately hosted, the mechanism is almost the same, black-box watermarking is used, except the model owner hosts the model privately. Model consumers gets access to the model via and API or gateway. First the model creator runs the watermark algorithm on his model and loads it to the hosting service. Then, via API access, users can query the model via inputs and obtains inferences as output. The backdoor is still public, so users can later verify the correct use of the model.
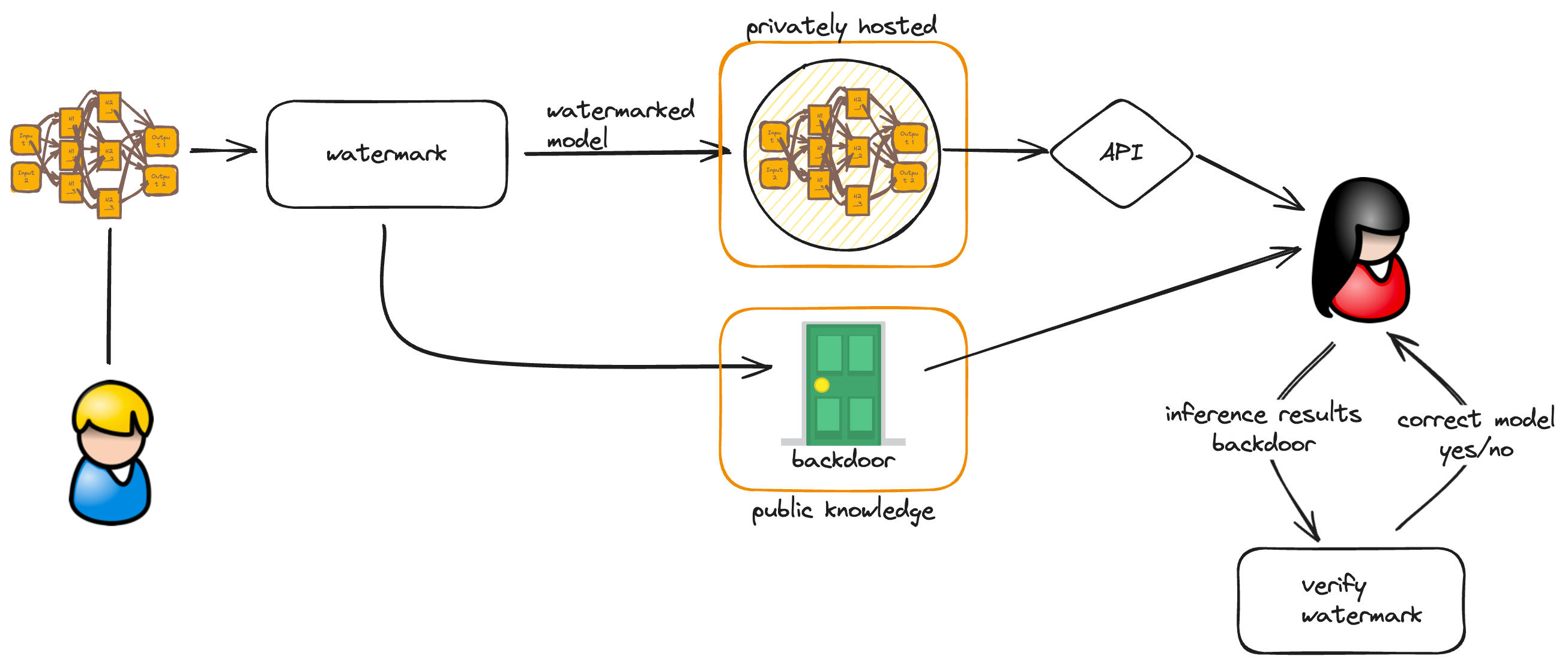
With knowledge of the backdoor, then users can run the verification algorithm to check for the watermark. The verification algorithm will tell if the correct model was used or not.
For private models offering API access, Xu and Yuan (2019) showed how to add unique serial numbers to the trigger-set of watermarks. Their serial number technique is independent of labels and can be supported by digital certification authorities.
Fingerprinting
How it works
Fingerprinting is a fascinating approach to model identification that differs from watermarking in a key way. While watermarking embeds a secret message into the model, fingerprinting relies on the model's inherent characteristics to create a unique identifier (Chen et al., 2019; Lukas et al., 2019). This identifier, akin to a digital DNA, can be transferred to any models derived from the original, making it a robust tool for proving model provenance.
A fingerprinting scheme consists of two essential components: a generation algorithm for creating fingerprints and a verification algorithm for confirming their presence.
Generate(M,D): Given white-box access to a modelMand a datasetD, this procedure outputs a fingerprintFand verification keysK={M(x) : x in F}.
The figure below illustrates the process of generating fingerprints.

Verify(M’(F),K): Given black-box access to a modelM’, fingerprintF, and verification keysK, this procedure outputs 1 ifM’is verified by the fingerprint and 0 otherwise.
Generating fingerprints is a complex task that requires a deep understanding of the model and its training data. One approach is to use adversarial examples. By adding carefully crafted noise to a correctly predicted data point, the model can be tricked into predicting a desired label. The data point and noise pair form an adversarial example, which can serve as a fingerprint.
Cao et al. (2019) demonstrated how to construct adversarial examples near the model's decision boundary and leverage their transferability to surrogate models. Peng et al. (2022) employed Universal Adversarial Perturbations (UAPs), which are vectors drawn from a low-dimensional subspace containing most normal vectors of the decision boundary. UAPs can function as a model's fingerprint, allowing the owner to verify if a given UAP vector v lies within the suspect model's UAP space.
In the following section, we will explore how fingerprints can be applied to verifiable inference. Fingerprinting provides a unique method for identifying models based on their inherent characteristics, distinguishing it from watermarking's embedded secret messages. As we delve further into this captivating topic, we will uncover the power of fingerprinting in ensuring model provenance.
Fingerprinting for Verifiable Inference
Public Models
When a model is public, the creator generates a fingerprint and keys, making them accessible to all. Consumers can download the model, fingerprint, and keys as a package.

With full access, consumers can modify the model through fine-tuning or compression. But how can they verify it's the genuine article?
Enter the verification algorithm. By running it on the query results and fingerprint, consumers can confirm the model's authenticity.
For public models, unique identifier fingerprints are crucial. Lukas et al. (2021) proposed a game-changing technique: conferrable examples. These crafted examples act as adversarial inputs not just for the target model, but also for any imitators. They transfer to surrogates but not to independently trained models.
Zhao et al. (2020) introduced adversarial marks, another transferrable fingerprint that can't be removed without sacrificing significant accuracy.
These innovative techniques ensure that public models remain trustworthy and authentic. They give consumers the power to verify, while creators can share their work with confidence.
In a world where AI models are increasingly open and accessible, fingerprinting is a vital tool. It's the key to maintaining trust and integrity in the face of modification and imitation.
So, the next time you download a public model, look for the fingerprint. It's your guarantee of authenticity in an ever-evolving AI landscape.
Private Models
Model creators may keep their models private to protect intellectual property rights. When generating a fingerprint, they can host the model privately and provide consumer access through a public API.

The verification algorithm for fingerprints always works on black-box access to the model. With public knowledge of the fingerprint, any consumer can verify it using the API.
Private models with public APIs are crucial for giving users access to LLMs like ChatGPT and Claude. However, LLMs pose a challenge in generating fingerprints due to their vast number of parameters.
Recent work by Gu et al. (2002), Li et al. (2023), and Xu et al. (2024) demonstrates how to construct fingerprints for LLMs. These methods implant input-output pairs that exploit the model's inherent characteristics.
Xu et al. (2024) presents the fastest fingerprinting method, claiming to fingerprint LLAMA2-13B in less than a minute using a single A100 GPU. Their technical contribution is that their methods can work in either white-box mode using an F-transformer or black-box mode using fine-tuning.
As AI continues to evolve, fingerprinting will play a vital role in ensuring the integrity of private models accessed through public APIs. It's a powerful tool that strikes a balance between accessibility and security.
TLDR
Verified inference is crucial in MLaaS, both centralized and decentralized. Consumers should be able to confirm the model generating the inference is the one they requested and paid for.
ZKML proves a model was executed on provided data, but compromises data privacy. Current ZK proof generation techniques are time-consuming due to cryptographic operations on top of the computation being proved (Garg et al., 2023).
ZKML allows perfect proofs of inference and provenance but struggles with real-time proofs for relevant deep neural networks like LLMs (GPT2, Llama).
Watermarking and fingerprinting fill the gaps. Practical and effective inference verification is a must in decentralized AI where trust cannot be assumed. Xu et al. (2024) generated fingerprints in the largest LLMs in under one minute.
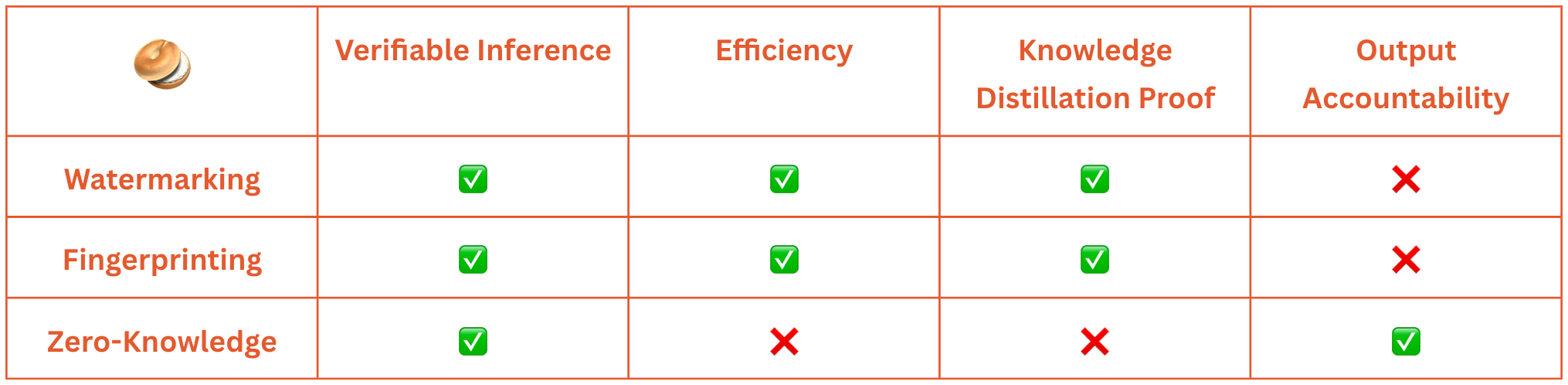
Verifiable inference is achievable through all three techniques. Watermarking and fingerprinting provide extraction and verification algorithms, while ZK offers proofs of knowledge.
Efficiency varies significantly. ZK is the slowest, while watermarking and fingerprinting can be fast, making them more applicable considering current state-of-the-art.
Knowledge distillation, a model compression attack, is a threat watermarking and fingerprinting are designed to protect against by passing the identifying markers to the compressed model. ZK does not address this issue, which is significant in the traditional AI industry and will be covered in a future article.
Output accountability is where ZK shines. While watermarks and fingerprints can establish ownership, they don't inherently ensure model integrity or output correctness. ZKPs prove a model was evaluated correctly on specific inputs, enabling accountability (Lederer et al., 2023; Oliynik et al., 2023).
As AI reshapes our world, we can't build the future on blind trust. Verifiability is essential for decentralized AI networks. We need transparency and accountability. AI's potential is vast, but honesty and integrity must come first. Watermarking and fingerprinting are key alternatives tools for that.
The stakes are high. We have to get this right.
Bagel is a deep machine learning and cryptography research lab. Making Open Source AI monetizable using cryptography.
Do you have an open-source repository where one can test/experiment with watermarked/fingerprinted models?
I have a general understanding of what was described but can't distinguish if this is a "perfect solution", such as asymmetric cryptography, or an additional layer such as those added to circumvent prompt injection.