



Return on Experience (RoE)
A single benchmark that predicts Reinforcement Learning's future.

Reinforcement learning (RL) evolves at headline speed. Each month brings a new “state‑of‑the‑art.” But we had to pause to ask one important question:
Can a single number line up every milestone so far and hint at the next leap?
We think maybe. We call that number Return on Experience (RoE). It’s an early phase benchmark.
What you read below is a lab notebook, handed down as working scripture. Feel free to share your peer review, or join the loop (what’s loop? more on that below).

New experience costs more than extra GPU time
When power is cheap, we can keep feeding a language model massive amounts of internet text at little extra cost.
But a surgical robot, a self-driving car, or an ICU-triage policy cannot just “scrape more experience”.
Every new trial burns tire, takes staff time, or waits for legal clearance.
In these settings the scarce resource is fresh experience - each environment step that has to happen in the real world.
Sample-efficiency is the art of squeezing the most learning from the fewest such experiences, and RoE is a meter for that exchange rate.
Recent AI breakthroughs point in an interesting direction
DeepSeek-R1-Zero improves reasoning capability through millions of GRPO self-play prompt-episodes. Meaning, the model practically “argue with itself” millions of times, turning each prompt-response into a tiny lesson, without requiring tons of human text.
OpenAI o3 tool use agent was trained to ask whether the next tool call (browser, code runner, or image) will actually move the answer forward. Each tool use carries an explicit cost during training, so the model invokes a tool only when the expected reward of that experience outweighs the cost.
DreamerV3 learns a world-model first, then practices inside that imagined space, harvesting thousands of virtual trials for every real one.
Different domains, same theme. Progress comes from squeezing more value out of each new experience. The next question is, how much result do we get per unit of experience? That ratio is RoE.
RoE compresses sample-efficiency into a single number that rises roughly logarithmically with progress.
The Formula
Let’s turn that idea into one formal equation.
Return on Experience (RoE) tells us how much “win” an RL agent buys per interaction it pays for. In other words, if you spend one unit of real world experience, how far does your performance score climb?
One step, one score, divided by weighted cost. Where,
headline score - the score a paper or a model brags about - Atari score, math-test accuracy, etc.
count - how many times the RL agent interacted with something while learning.
weight - Not all interactions are equal. Weight adds a rough price tag for each kind of interaction because some are costly and some are cheap.
real-world action = 1 (full price)
calling an external tool (e.g. OpenAI o3) ≈ 0.01
self-play or a step inside a learned simulator (e.g. DeepSeek-R1-zero) ≈ 0.001
We think of the weights as discounts. Because some synthetic/simulated steps cost a thousandth of a real-world step, tool calls cost about two hundredth.
This way, RoE lets us put a language model, a robot arm, and a video-game agent on the same chart. High RoE means the agent climbs the leaderboard quickly and keeps the cost for fresh experience low. Low RoE means it wastes a lot of real-world practice for each bump in score.
A short history of RoE Loops
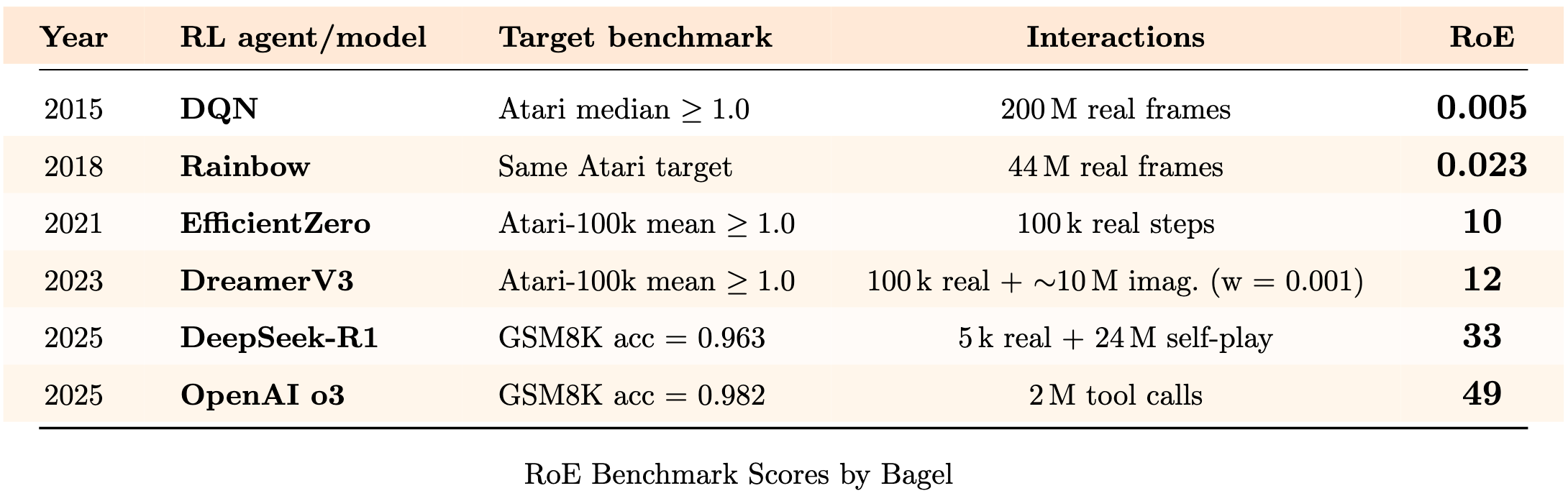
Below we cast some historical milestones of Reinforcement Learning into the RoE benchmark, to show RoE could predict the performance of them.
We call each big RoE jump a loop - one full turn of experience → insight → back to model/agent. Like the closed-loop theorem (or a bagel ring).
But first, some info on the classic benchmarks used to calculate RoE,
Atari - 57 classic video games used as a standard obstacle course for RL.
Human-normalised score takes a human play-through on each game, sets that to 1.0, then shows how far the agent climbs above it.
Median is the middle game after ranking all 57 scores; a quick “overall” health check.
Atari-80k / Atari-100k mean looks at the average score but limits the agent to only 80k or 100k game frames, so we can see who learns fastest, not just who learns best.
GSM8K - 8.5k grade-school word problems. For each problem an RL agent writes one answer. Pass@1 is simply the percentage of problems it gets right on that very first try.
Here is a worked example of RoE calculation with OpenAI o3,
For o3, headline_score = 0.982, weight = 0.01, interaction count = 2M.
So, according to our RoE equation above,
Observations,
Rainbow quadrupled RoE over DQN by upgrading loss functions and replay, proving that better optimization alone can unlock large efficiency from same amount of experiences.
EfficientZero learned to plan inside a latent world model instead of in the real world. With most interactions being synthetic, RoE passed 10.
DreamerV3 pushed the same idea further. Over 90% of the experiences were simulated. Real-world performance climbed with very little new real-world experience.
DeepSeek-R1 brought model self play into the limelight. Model debates with itself on each problem, boosting GSM8K accuracy while keeping the new and cost heavy experience ledger small.
Cost-aware tool use has been another RL win of 2025. OpenAI o3 trained the RL agent to accrue a cost while calling a tool. That optimized RoE to ~50.
Prediction for the next 5 years
RoE has grown on a log curve - 0.023 for Rainbow (2018) up to about 50 for OpenAI o3 (2025). There’s no sign that the slope is flattening. World-model research, sample-efficient policy optimization and a coming surge in cheap compute all point the same way.
Below is a 5 year prediction on RoE numbers, and examples of what that could mean, inspired from peer-reviewed academic work,
(We count the past jumps - Rainbow through o3 - as Loops 1-5.)
Loop 6 - Year 2026 - RoE ≈ 150
World-model research will slip from Atari into the operating room. Hospitals will train surgical robots almost fully in world-model simulators such as Surgical Gym and ORBIT-Surgical. A bot will practise thousands of virtual stitches for before doing a real one.
Loop 7 - Year 2027 - RoE ≈ 1000
Scaling labs will run foundation world-models such as Genie on ~30x cheaper compute hardware. Agents will write and test entire NeurIPS papers inside those generated 3D sandboxes, requiring only high-level edits from humans. RoE will move past the four-digit mark.
Loop 8 - Year 2028 - RoE ≈ 3000
Self-play on synthetic molecule sets will reduce wet-lab screening from tens of thousands of assays to a few hundred. Drug-discovery will be massively accelerated. RoE will keep its log-pace and enter “several thousand” territory.
Loop 9 - Year 2029 - RoE ≈ 8000
Regulators will approve the first cargo aircraft whose flight-control laws are proved largely in simulation-based certification workflows. One hour of real flight data will be enough to sign off.
Loop 10 - Year 2030 - RoE ≈ 12000
Companies will field “digital graduates” - ~30B parameter reasoning models trained with Dr. GRPO style length-penalised objectives. Each will master a new technical field from a few annotated pages, then draft patents, close mergers and rewrite tax law overnight. One human auditor will review the output of a thousand such agents.
We, at Bagel, are accelerating the next RoE Loops through open-source AI. If you want to be one of the ones leading frontier experiments in uncharted territories, we’re hiring. Come build the next loop yourself.
I appreciate the readability and common sense thinking of this piece. RoE makes sense intuitively, but it is also wild to see just how high these numbers will likely climb in the coming months and years.
Cost-aware tool usage and world model research will become the norm this year. And, exciting to see the direct applicability to solving real-world use cases.
This is worth checking out
https://substack.com/@cortexmuteek?r=5re9la&utm_medium=ios