





Synthetic data is AI's new secret weapon. It solves major challenges of using real-world data.
Consider privacy. Industries like finance, drug discovery, medical imaging can work around strict data sharing restrictions through synthetic data. It mimics real world data without exposing personal information, allowing for secure, regulation compliant AI development.
Training AI for rare, extreme scenarios is also vital, but often impossible with real data. Synthetic data solves this problem. It can simulate events like uncommon car accidents to train autonomous vehicle. This vastly expands the scope and robustness of AI systems.
Another persistent issue is bias in datasets. Real data often reflects historical prejudices or demographic imbalances. Synthetic data enables the creation of balanced datasets that counteract these biases, leading to fairer AI systems.
AI development needs rapid access to vast amount of quality data. Real data collection and processing has overhead. Synthetic data can be generated instantly, supporting fast testing and iteration with diverse datasets. It improves model accuracy while cutting the need for data labeling and collection drastically.
This article takes you on a journey into the fascinating world of synthetic data. We'll uncover the top techniques used to create it. We'll see how it's solving critical problems across sectors. And we'll give you an unfiltered look at the pros and cons you need to know. Or how you can implement it for your specific business need.
If you're in a rush, we have a TLDR at the end.

How To Generate Synthetic Data
Synthetic data is statistically accurate simulations of real-world datasets. Two forms of it exist: fully synthetic data, created without real data, and partially synthetic data, which may include original dataset elements.
Data quality depends on generation technique and type. In this article, we have explored three major useful synthetic data generation technique families Generative, Evolutionary, and Marginal-based. Technique choice depends on data type (tabular, time-series, images) and desired properties (diversity, realism, privacy).
Generative Methods
Generative AI has had a big impact across all industries pushing teams to perform at a higher rate. The goal of generative AI is essentially to generate new data, be it image, audio, video, text, etc. It is, thus, natural to rely on generative AI techniques to create new synthetic data.
Below we discuss three of the most popular generative synthetic data generation methods below, Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs) and Diffusion Models.
1. Variational Autoencoders (VAEs)
A Variational Autoencoder (VAE) is an algorithmic tool that compresses and decompresses data. VAEs are practical tools used in diverse fields such as computational chemistry for generating molecular graphs, anomaly detection in data streams, and even in game design to create diverse and complex environments.
The goal of VAEs is to transform data points from a high-dimensional space, to a lower-dimensional, more meaningful latent space. The transformation process involves two main components: the encoder and the decoder. The encoder's task is to map data to the latent space, while the decoder reconstructs the data back to the original high-dimensional space. The goal is to minimize the error between the original and reconstructed data, denoted as
where x is an input, E and D denote the encoder and decoder functions, and ϵ is an error function.
A VAE differs from a standard autoencoder by introducing a probabilistic twist. The encoder in a VAE doesn't directly output coordinates in the latent space. Instead, it outputs parameters to a probability distribution—typically a Gaussian denoted by
where μ denotes the mean and σ it’s standard deviation where both can depend on the input x. The figure below shows the general architecture of a VAE.
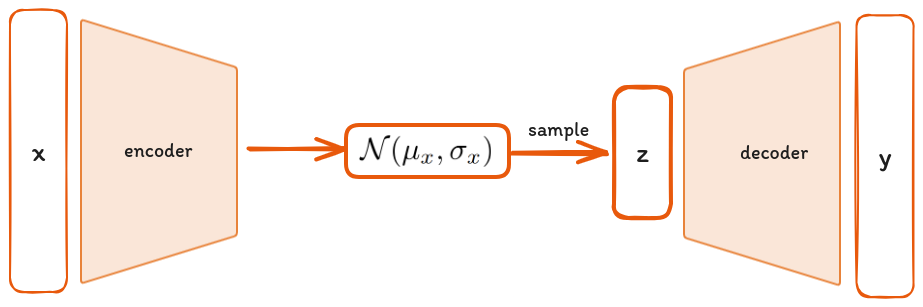
The decoder samples from the distribution generated by the encoder to generate new data points, effectively turning the decoder into a generator of synthetic data. This process is governed by a loss function L, which balances two terms
where KL denotes the Kullback-Leibler divergence, a measure of how one probability distribution diverges from a second, expected probability distribution.
Pros
Data Type Flexibility. VAEs are adaptable to various data types, including multimodal data.
Anomaly Detection. It excels in identifying data points that deviate significantly from the norm, as these will have high reconstruction errors.
Efficient Sampling. Post-training, sampling from the latent space and generating new data via the decoder is straightforward and efficient.
Cons
Loss Function Balancing. The dual nature of the loss function, combining reconstruction and regularization, requires careful tuning, which is still an active area of research (Asperti et al. 2021).
Blurriness in Output. Often, the output images or data from VAEs lack sharpness (Asperti 2020).
Clustering in Latent Space. In scenarios where the dataset inherently contains subcategories, these often manifest as clusters in the latent space, which can be problematic for generative tasks where uniformity might be desired (Asperti et al. 2021).
2. Generative Adversarial Networks (GANs)
In a Generative Adversarial Networks (GANs), two AI algorithms are locked in a game competing against each other. We have two neural networks, the generator (G) and the discriminator (D), engaging in a continuous game of deception and detection. The generator strives to create data so authentic that the discriminator cannot distinguish it from real data. Conversely, the discriminator's goal is to accurately identify whether the data it reviews is genuine or fabricated by the generator. This dynamic competition drives both networks towards perfection, simulating a game where the prize is the ability to replicate reality.
GANs have found their way into various industries showcasing their versatility. NVIDIA, for instance, uses GANs to create lifelike artwork and to transform 2D images into 3D shapes. eBay employs them for image-based search functionalities in their marketplace. Audi leverages GANs for innovative wheel design, while Zalando generates new textures for the fashion industry.
In a GAN, the generator crafts fake data, aiming to pass it off as real. The discriminator tries to separate the true from the false. This process is a high-level game, where each player sharpens their skills in response to the other's moves. The generator uses input 𝑥 from a distribution p corresponding to a random variable X to produce output aiming to mimic a target distribution T. The discriminator examines outputs 𝑦=𝐺(𝑥), guessing if they're real or fake. Ideally, the generator's output distribution 𝐺(𝑋) aligns so closely with 𝑇 that the discriminator is left guessing, assigning a 50% probability to both real and fake data.
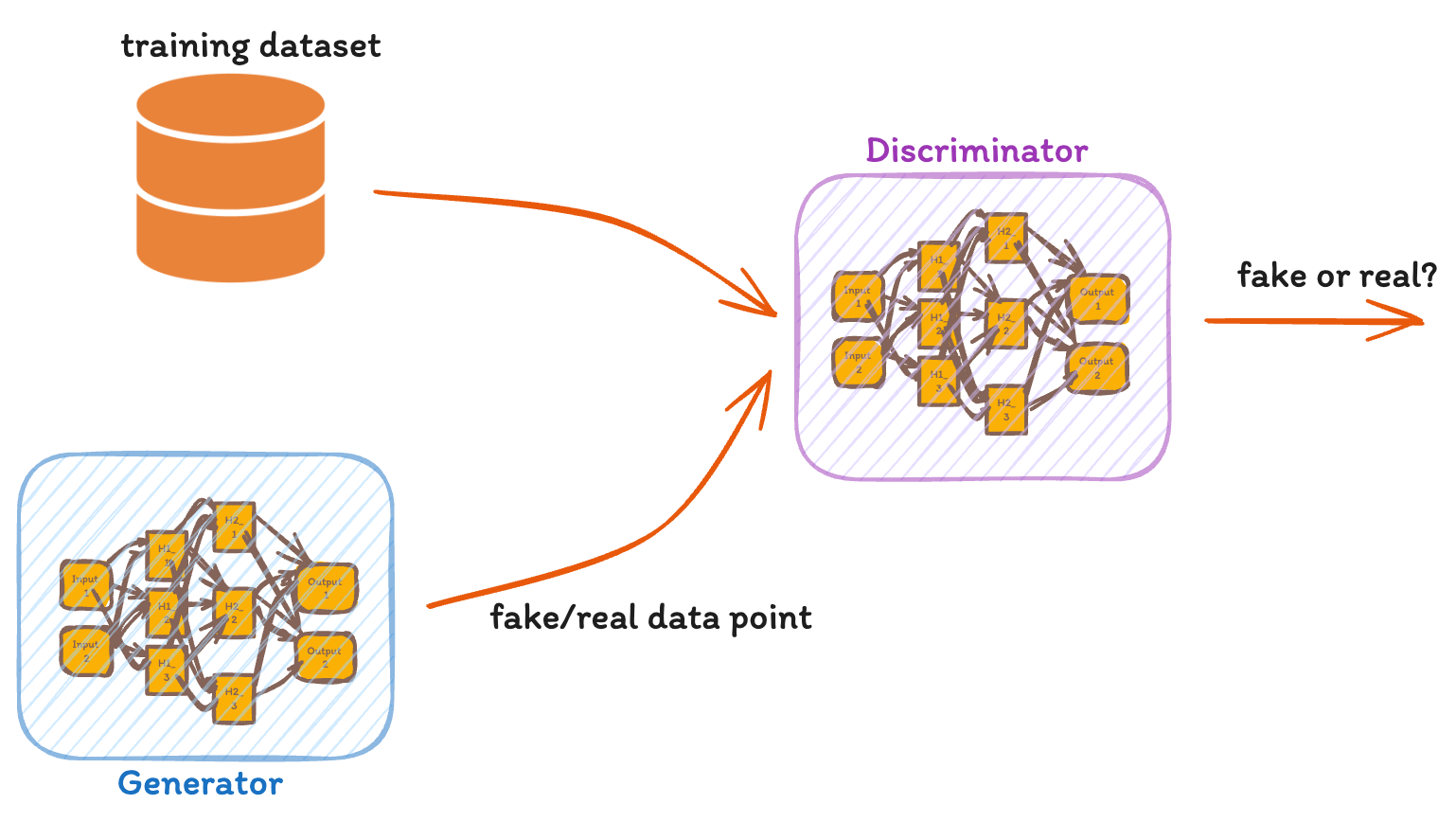
Pros
Anomaly Detection. GANs excel in identifying outliers, making them invaluable for tasks like fraud detection.
High-Quality Outputs. They are capable of producing images so realistic that they can fool the human eye.
Privacy Protection. Incorporating differential privacy during training ensures sensitive data remains secure.
Cons
Mode Collapse. A scenario where the generator produces limited varieties of output, making it easier for the discriminator to identify fakes.
Training Challenges. Balancing the training pace of both networks is crucial, yet difficult, to ensure both improve simultaneously.
Non-Convergence. The unique loss function of GANs can lead to challenges in achieving convergence through gradient descent.
3. Diffusion Models
Diffusion models represent an alternative generative AI approach, primarily used for creating synthetic images. They appear in the automatic generation of high-resolution images and videos where notable implementations include Stability AI's Stable Diffusion, OpenAI's Dall-E and Sora, and Meta's ventures into 3D image generation. These models operate through a dual-process system: a forward diffusion that adds noise, and a reverse diffusion that reconstructs the image. This method offers a robust framework based on principles of non-equilibrium thermodynamics.

The forward diffusion is a Markov chain process. It incrementally introduces Gaussian noise into an image, transforming it step-by-step into a noisy version. This process is mathematically represented as:
The mean of the normal distribution is
and the variance is
The sequence β1,…,βt, known as a schedule, varies between 0 and 1.
The reverse diffusion employs a deep neural network, specifically a U-Net architecture, to reconstruct a new image from the noisy data. The goal is to learn a probability distribution
where θ represents the model parameters. Training this model involves maximizing the likelihood of matching the learned probability distributions of the equation above with the original distributions q.
Pros
Theoretical foundations. These models are grounded in the solid theoretical frameworks of thermodynamics and differential equations.
Efficient inference. They are capable of generating high-resolution images efficiently, even on personal computing devices.
High-quality outputs. The images produced are detailed and realistic, making them central to technologies like Dall-E and Sora.
Cons
Training time. Developing a diffusion model from scratch demands significant computational resources and expertise.
Complexity. A deep understanding of the underlying theoretical principles is necessary to effectively implement and optimize these models (Karras et al. (2024).
Evolutionary Methods
Evolutionary methods comprise a collection of algorithms and techniques that iteratively construct synthetic data from a seed dataset. By applying certain operations of combination and mutation of data points, evolutionary methods look to generate synthetic data that is diverse and deep in the context of the initial dataset.
1. Genetic Algorithms
The algorithm Private-GSD (Private Genetic Synthetic Data) proposed by Liu et al. (2023) is a genetic algorithm designed to generate synthetic data that approximates the statistical properties of an underlying sensitive dataset while ensuring differential privacy. It leverages principles from biological evolution to iteratively optimize a population of synthetic datasets. By applying selection pressure and introducing variation through mutation and recombination, these methods evolve datasets that can produce increasingly diverse and high-quality synthetic examples over generations.
The process of Private-GSD is shown in the figure below.

Initialization: Private-GSD starts with an initial population of synthetic datasets randomly generated. Each dataset in this population is a candidate solution to the problem of generating synthetic data that closely matches the statistical properties of the original dataset.
Evaluation: Each candidate synthetic dataset is evaluated based on how well it approximates the statistical queries of interest on the original dataset. This evaluation is quantified using a loss function that measures the difference between the statistical properties of the synthetic and original datasets.
Selection: The algorithm selects a subset of the best-performing synthetic datasets from the current population. These datasets are considered "elite" and are carried over to the next generation.
Crossover and Mutation: Private-GSD generates new synthetic datasets by combining features from the elite datasets (crossover) and introducing random changes (mutations) to some of these datasets. This process is inspired by genetic recombination and mutation in biological evolution.
Iteration: Steps 2 through 4 are repeated for a specified number of generations or until a convergence criterion is met. With each iteration, the population of synthetic datasets evolves, ideally becoming better approximations of the original dataset's statistical properties.
Output: The algorithm outputs the best-performing synthetic dataset from the final generation.
Pros
Flexibility. Private-GSD can generate synthetic data that approximates a wide range of statistical queries, including those that are non-differentiable and thus challenging for other algorithms that rely on gradient-based optimization.
Privacy Preservation. By design, Private-GSD ensures differential privacy, making it suitable for generating synthetic data from sensitive datasets without compromising individual privacy.
No Requirement for Differentiability. Unlike methods that rely on gradient-based optimization, Private-GSD does not require the objective function to be differentiable. This allows it to work with a broader range of statistical queries.
Cons
Computational Complexity. The iterative nature of genetic algorithms, combined with the need to evaluate multiple candidate solutions in each generation, can make Private-GSD computationally intensive, especially for large datasets and complex statistical queries (Liu et al. 2023).
Parameter Sensitivity. The performance of Private-GSD can be sensitive to its hyperparameters, such as the size of the population, the number of generations, and the rates of crossover and mutation. Finding the optimal set of parameters may require extensive experimentation (Liu et al. 2023).
Convergence Guarantees: While Private-GSD is designed to improve the approximation of statistical properties over generations, there may not be strong theoretical guarantees on the convergence rate or the quality of the final synthetic dataset compared to the original dataset (Liu et al. 2023).
2. Self-instruct
The process of training Large Language Models (LLMs) to follow instructions often involves labor-intensive tasks, particularly in dataset creation. OpenAI, for instance, employed numerous annotators to develop an open-domain instruction dataset for training InstructGPT. Conversely, Vicuna utilized around 70,000 user-shared conversations from ShareGPT.com to fine-tune a LLaMA model. Human annotation introduces notable challenges. According to Xao et al. (2023), these include the tendency of human-created instructions to skew towards easier levels and the issue of annotator fatigue, which limits the production of complex instructions over extended periods. This can lead to LLMs generating hallucinations. To counter these issues, synthetic open-domain instruction data generation is essential.
In computational linguistics, Self-instruct was developed by Wang et al. (2022) as a technique that leverages the inference capabilities of LLMs to generate synthetic, open-domain instruction data. Self-instruct was used in Alpaca, a fine-tuned LLM from Stanford, and it was a key component in the tech stacks of AI companies like Continuum Labs and Lightning AI. This showcases the technique's practical value and versatility.
The process of Self-instruct begins with a seed set of manually-written tasks. This initial step is crucial as it lays the foundation for the model to generate new instructions. GPT-3 is chosen for its robust inference capabilities. It's tasked with a simple job: take an instruction and an input, and produce an output.

Generating Task Instructions. Starting from a pool of 175 tasks, the model starts generating new instructions. In each iteration, a mix of human-written and model-generated instructions are used to enrich the task pool, ensuring diversity and complexity.
Task Discrimination: Classification or Not? This stage involves discerning whether a task is a classification task. The model is prompted with a mix of classification and non-classification instructions to make this determination, a critical step for tailoring the generation approach.
Crafting Input-Output Pairs. Depending on the task's nature, the model adopts either an input-first or output-first strategy. This bifurcation allows for a more nuanced generation of data, aligning closely with the task's requirements.
Filtering and Postprocessing. The final step involves filtering to ensure quality. Using metrics like ROGUE-L similarity, the model removes redundant or low-quality instructions, refining the task pool to only include the most unique tasks.
Pros
Diverse Instruction Sets. By generating instructions from the model itself, Self-instruct facilitates the creation of a more diverse and creative set of tasks.
Cost-effectiveness and Scalability. Generating instructions using the model itself is more cost-effective compared to the traditional method of collecting large-scale human-annotated datasets.
Reduction in Dependency on Human-Written Instructions. Self-instruct minimizes this dependency by generating its own instructions.
Cons
Model Dependency: The technique's reliance on a specific LLM inherits its limitations (Wang et al. 2022).
Bias Reinforcement: There's a struggle to produce balanced labels, inadvertently amplifying the model's inherent biases (Wang et al. 2022).
Dataset Growth Plateau: The exponential growth of new instructions eventually levels off, indicating a saturation point (Wang et al. 2022).
3. Evol-instruct
Evol-instruct is a technique revolutionizing the creation of synthetic open-domain instruction data across various difficulty levels. Evol-instruct has been instrumental in projects like Ragas's RAG pipeline and the WizardCoder LLM, surpassing models like Anthropic's Claude and Google's Bard in performance. Its application continues to expand across AI enterprises, like Clarifai, demonstrating its pivotal role in advancing LLM capabilities.
The core concept involves evolving a known set of instruction-answer pairs over a series of epochs, each designed to enhance the dataset's complexity, richness, and diversity.
The initial dataset comprises pairs of instruction-reply of the form
for 𝑘 instructions. Each epoch 𝑡 updates the dataset to D(t+1) by refining each instruction 𝐼(𝑡) through a prompt to an LLM, which then generates an improved instruction 𝐼(𝑡+1). This new instruction is used to obtain a corresponding answer R(𝑡+1). After 𝑀 epochs, this iterative process results in multiple datasets 𝐷(1),…,𝐷(𝑀).
The evolution process bifurcates into two types of prompts: in-depth and in-breadth evolving. In-depth evolving involves enhancing instructions through adding constraints, deepening content, concretizing details, increasing reasoning steps, and complicating inputs. Each modification aims to incrementally raise the instruction's difficulty, with a word limit of 10 to 20.
In-breadth evolving, on the other hand, focuses on generating new instructions from existing ones to broaden topic and skill coverage and enhance diversity.

An additional step, Elimination evolving, filters out unsuccessful instruction evolutions. An instruction is deemed unsuccessful if it adds no new information, complicates response generation for the LLM, consists only of punctuation and stop words, or merely copies words from the prompt.
Upon completing all epochs, the instruction-answer pairs from 𝐷(1),…,𝐷(𝑀) are shuffled randomly to ensure a uniform distribution of varying difficulty levels.
Pros
Variety and Challenge. The technique excels in generating tasks of varying difficulty, pushing the boundaries of what models can learn (Xu et al. 2023).
Quality. Human annotator experiments reveal superior performance on complex instructions, showcasing the high caliber of the synthetic dataset (Xu et al. 2023).
Cons
Failure Rate in Instruction Evolution. The Evol-instruct method sometimes fails during the instruction evolution process (Xu et al. 2023).
Complexity Management. While Evol-instruct is designed to increase the complexity of instructions, managing this complexity effectively is challenging. There is a risk of generating instructions that are too complex (Xu et al. 2023).
Quality Control. Ensuring consistent quality across the evolved instructions is another challenge. The method relies heavily on the initial quality of the seed instructions and the effectiveness of the LLM used in the evolution process (Xu et al. 2023).
Marginal-based Methods
Marginal-based methods focus on modelling the marginal distributions and inter-attribute dependencies in the original data. They typically construct a probabilistic model, such as a graphical model or Bayesian network, to capture these statistical properties. Synthetic data is then generated by sampling from this model. Some marginal-based methods provide rigorous guarantees of differential privacy, making them well-suited for tabular data synthesis when preserving privacy is crucial.
Marginal-based methods is a nascent field in private synthetic data and it is still looking to be adopted in relation to other competing techniques like GANs. Tumult Labs is looking at these techniques and currently researching its potential.
1. Multiplicative Weights Exponential Mechanism (MWEM)
The MWEM (Multiplicative Weights Exponential Mechanism) algorithm proposed by Hardt et al. (2010) is designed for differentially private data release, particularly focusing on producing synthetic datasets that respect differential privacy while answering a set of linear queries. The algorithm is a combination of the multiplicative weights update rule and the Exponential Mechanism, which are used to iteratively refine an approximation of a dataset in a way that balances privacy and accuracy.
Let D be a dataset with d columns. A marginal for a subset r of the d columns is a histogram for r, that is, a table that counts the number of occurrences of tuples with columns in r. A marginal is often referred to as a marginal query. A workload W is a collection of marginal queries. A marginal-based method takes a workload as input, then it adapts intelligently to the queries in the workload, and generates synthetic data that is tailored to these queries.
The MWEM has three main components. A Multiplicative Weights Update Rule that is used to adjust the weights of an approximating dataset to better reflect the true dataset based on the discrepancies in query responses. The Exponential Mechanism selects the most informative queries to improve the dataset approximation. The Laplace Mechanism for adding noise to the query results to ensure differential privacy.
The MWEM algorithm proceeds as shown in the figure below.

It starts with an initial approximation of the dataset, typically a uniform distribution over the data domain. Then it uses the exponential mechanism to select a query that is poorly explained by the current approximation. Then the selected query on the true dataset is measured, adding noise via the Laplace mechanism to ensure privacy. These steps of select-measure are repeated for a number of iterations. Finally, the output is an average of the approximations across all iterations, which forms the synthetic dataset.
An improved algorithm based on MWEM was developed by McKenna et al. (2022), where MWEM is enhanced with the Probabilistic Graphical Model or PGM and the Gaussian mechanism is used instead of the Laplace mechanism.
Pros
Privacy. MWEM is designed with differential privacy mechanisms (McKenna et al. 2022).
Effectiveness. MWEM+PGM is currently the best method for generating synthetic data with privacy guarantees (Tao et al. 2023).
Cons
Limited data types. MWEM have only been tested on discrete data. Much research still needs to be done in categorical and numerical data (McKenna et al. 2022).
Lack of maturity. The field of marginal-based methods is very recent, and still much research is needed to have a good understanding of its impact and applications (Ponomareva et al. 2023).
2. PrivBayes
PrivBayes is a differentially private method proposed by Zhang et al. (2017) for releasing high-dimensional data, which is effective when dealing with datasets that contain a large number of attributes. The algorithm operates in three main phases: network learning, distribution learning, and data synthesis.
In the first phase, PrivBayes constructs a Bayesian network that approximates the full-dimensional distribution of the dataset. This network is built using a differentially private method, ensuring that the privacy of the data is maintained. The Bayesian network is a graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph.
Once the Bayesian network is established, PrivBayes computes a set of differentially private conditional distributions for the data in the subspaces defined by the network. This involves adding noise to the distributions to ensure differential privacy, typically using mechanisms like the Laplace mechanism.
In the final phase, PrivBayes uses the noisy conditional distributions and the structure of the Bayesian network to generate a synthetic dataset. This dataset is an approximation of the original data but is constructed in such a way that it maintains the privacy of the individuals in the dataset.
Pros
Handling High-Dimensional Data. PrivBayes handles the challenge of releasing high-dimensional data, which is always a barrier for traditional differential privacy methods.
Reduced Noise Addition. By focusing on low-dimensional marginals, PrivBayes can inject less noise resulting in higher utility of the released data.
Flexibility in Query Evaluation. The synthetic data generated by PrivBayes can support a wide range of queries allowing the estimation of various statistical properties.
Scalability. The method scales well with the size of the data and the number of attributes, making it suitable for large datasets.
Cons
Complexity in Network Construction. The process of learning a differentially private Bayesian network is complex and can be computationally intensive.
Accuracy Dependence on Network Quality. The accuracy of the synthetic data heavily depends on the quality of the Bayesian network constructed.
Parameter Sensitivity. The performance of PrivBayes can be sensitive to the choice of parameters, such as the privacy budget allocated to different phases of the algorithm.
TLDR
This is a quick summary of the key points covered in the article about different techniques for generating synthetic data for machine learning.
Generative Methods use AI models to generate new synthetic data. Popular techniques include Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Diffusion Models. VAEs compress data into a lower-dimensional space and then reconstruct it, allowing for data generation. GANs have two competing AI models, a generator creating fake data and a discriminator identifying real vs. fake data. Diffusion Models gradually add noise to an image and then learn to reverse the process, generating new images.
Evolutionary Methods iteratively construct synthetic data from a seed dataset by applying operations like combination and mutation. Techniques like Private-GSD use genetic algorithms, while Self-instruct and Evol-instruct leverage large language models to generate and evolve open-domain instruction data.
Marginal-based Methods model the marginal distributions and inter-attribute dependencies in the original data using probabilistic models like graphical models or Bayesian networks. Synthetic data is then generated by sampling from these models. Techniques like MWEM and PrivBayes provide differential privacy guarantees, making them suitable for sensitive tabular data.
The table below summarizes the different aspects of the methods.

Synthetic data is disrupting the AI industry status quo. As techniques like generative models, evolutionary methods, and marginal-based approaches continue to advance, the potential applications of synthetic data are boundless. Embracing this technology can empower businesses to unlock more accessible, reliable, and impactful AI.
Bagel is a deep machine learning and cryptography research lab. Making Open Source AI monetizable using cryptography.